
Datalake, database, data warehouse: parole che chiaramente si riferiscono ai dati e alla loro archiviazione ma con quale significato? Si equivalgono? Come possono essere utili nel sales e field marketing?
È innegabile: datalake, database, data warehouse sono parole di cui tutti hanno sentito parlare, ma è altrettanto vero che perlopiù solo gli “addetti al lavoro” conoscono le reali implicazioni sul modo di lavorare e nelle strategie di business. Non a caso sono tra le parole “tecniche” più ricercate su Google nel corso degli anni.

Questo articolo non vuole essere un altro vademecum di mere definizioni, bensì un breve testo cui ci proponiamo di fare più chiarezza su quanto questi tre strumenti siano ormai cruciali per brand, retailer e per noi che operiamo come partner nelle vendite.
Come e perché
Per comprendere il come e il perché è necessario partire dall’origine, dal dato. Come dicono tutti gli esperti di business e strategia “data is the new fuel”: numeri, dati e insight sono il principale catalizzatore per la crescita e la competitività. Sono il modo con cui è possibile individuare nuove opportunità di business, ottimizzare le attività aziendali, prevedere le tendenze di mercato, identificare aree di risparmio dei costi, conoscere le proprie audience, rispondere ai trend di consumo ecc.... Ma i dati in sé non generano valore aggiunto, lo si ottiene solo se vengono raccolti, preparati, analizzati e usati correttamente. È necessario attivare un’adeguata Data Literacy, ovvero bisogna creare quella capacità analizzare e elaborare i dati per generare informazioni utili a supportare le decisioni aziendali. Ed è proprio qui il busillis: le informazioni che le aziende collezionano sono numerosissime ed estremamente varie e i tradizionali database - che raccolgono i dati in relazione tra di loro e sono interrogabili direttamente o attraverso una o più applicazioni - non sono più sufficienti alla loro gestione. Si pensi soltanto a quante informazioni numeriche, testuali e fotografiche si possono raccogliere su un punto vendita per comprendere il comportamento d’acquisto di un consumatore. Con l’avvento di data science, business intelligence e business analytics archiviare, organizzare e analizzare, numeri immagini complesse, disegni e prodotti multimediali è sempre più difficile. Il rischio è che un database, anche uno dei più complessi, possa rimanere «isolato» non permettendo la facile condivisione delle informazioni contenute. Ed è qui che entrano in giorno i datalake e data warehouse.
Oltre il database
Anche datalake e data warehouse si occupano di archiviazione dati, ma con capacità che vanno ben oltre quelle di un database dal momento che sono in grado di favorire l’uso degli analytics. E sono diventati talmente rilevanti che hanno rilevanza economica: secondo Mordorintelligence le dimensioni del mercato dei Data Lake si prevede cresceranno da 13,74 miliardi di dollari nel 2023 a 37,76 miliardi di dollari entro il 2028, con un tasso di crescita annuo composto (CAGR) del 22,40% durante il periodo previsto (2023-2028).
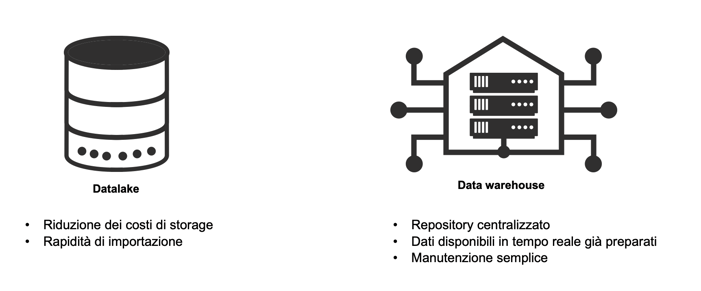
Ma cos’è un datalake? E’ un repository nel quale i dati sono archiviati nel loro formato nativo, senza cioè che vengano preparati e prelavorati. Questo perché un dato che entra nel datalake non ha ancora una destinazione d’uso ben precisa e verrà preparato solo quando sarà necessario utilizzarlo per le analisi. In altre parole, qui archiviamo immagini, commenti, numeri: per esempio la fotografia di uno scaffale, le dimensioni di un espositore, un commento di un user online ecc… E quali sono i vantaggi? Sicuramente una significativa riduzione dei costi di storage, ma anche una rapidità e facilità nell’importazione dei dati. Al contrario del datalake il data warehouse è un repository che acquisisce, prepara e archivia dati da differenti fonti per uno scopo ben preciso e definito. I data warehouse vengono costruiti sui database relazionali, intervengono con ulteriori azioni di data preparation, con fasi di pulizia e trasformazione per migliorare la qualità del dato, a tutto vantaggio delle applicazioni analitiche. Il funzionamento di un data warehouse segue il processo chiamato ETL che prevede le tre fasi di estrazione, trasformazione e caricamento (extract, transform and load in inglese), successivamente il dato viene preparato attraverso altre fasi (data discovery, data cleaning, data transformation, data enrichment, data validation) e caricato sul sistema in modo da essere fruibile agli analitycs. Pensando a un esempio concreto, i dati raccolti e prelaborati permetto al cliente di avere informazioni dettagliate sul posizionamento di una tipologia di prodotti all’interno del punto vendita, dalle quali elaborare nuove strategie e tattiche per migliorare e ottimizzare il merchandising. In sintesi, offre una visione olistica di prestazioni, distribuzione, visite e touch point. Quali sono i vantaggi? Il primo è il repository centralizzato, poi la possibilità di accedere a dati in tempo reale, già preparati e, infine, una semplice manutenzione.
La tecnologia in CPM
I dati sono sempre stati parte del business di CPM, ma oggi ci danno una spinta in più. Abbiamo la tecnologia necessaria per poter processare grandi quantità di dati provenienti dai nostri sistemi di data capturing, dai nostri clienti e da terzi parti, che grazie al nostro team di business intelligence organizziamo secondo le logiche dei database relazionali. Sono tutte le informazioni utili a supportare i nostri processi analitici day-by-day garantendoci le condizioni di affidabilità e qualità che abbiamo definito e per le quali ci siamo impegnati con i nostri clienti. Queste informazioni di tipo quantitativo e qualitativo vengono poi analizzate e interpretate in modo da fornire business insight azionabili per i nostri clienti, utili anche a definire la strategia di canale e di presidio del punto vendita per il futuro.
Scopri di più su come utilizziamo i dati qui
Leggi anche: L’articifico dell’IA

 3 minute read
3 minute read


